はじめに
(元)AppBrewエンジニアインターンのSora (@9bluesky6) / Xです。 2023年の9月に大学院の卒業と同時にAppBrewも卒業し、10月からはGoogleで働いています!
2020年の8月から(半年の休職を挟みつつ)3年間、主にバックエンドエンジニアとしてLIPSの開発に関わらせていただきました。 そのため卒業を機会に私がどうやって入社して、どんなインターンライフを送ってきたのかを紹介していきたいと思います。
現在もAppBrewは絶賛インターン募集中なので、興味がある学生さんの参考になれば嬉しいです!
入社したきっかけ
B4だった2020年の7月、コロナ禍でアルバイト難民だったため、リモートでできる開発インターンのポジションを探していました。 そんな折、現CTOのPinさんにTwitter(当時)でフォローされたことがAppBrewを知ったきっかけでした。
元々LIPSのユーザーだったこと、美容に興味があったこと、また同じ学科の方が当時インターンとして働いていて楽しそうだなーと思い応募することを決めました。 特にインターン求人は見つけられなかったので、PinさんにDM凸して面接をしてもらうことになりました。
入社時のスキルセットは、学部の授業とFuelPHPでのバックエンド開発経験があり、またGoogleの教育プログラムであるSTEPを修了していました。LIPSで主に使用されているRailsの経験はなかったため、 Rails チュートリアルからスタートしました。
仕事内容
チュートリアルが終わったあとは、バックエンド、フロントエンド、自然言語処理タスクなど幅広いIssueに取り組ませてもらいました。
具体的な施策をいくつか紹介します。
SEO対策の一つとして、Googleの新しいSEO指標であるCore Web Vitalsに対応した改善を行いました。詳しくは以前ブログ記事を執筆したので、こちらをご覧ください。 tech.appbrew.io
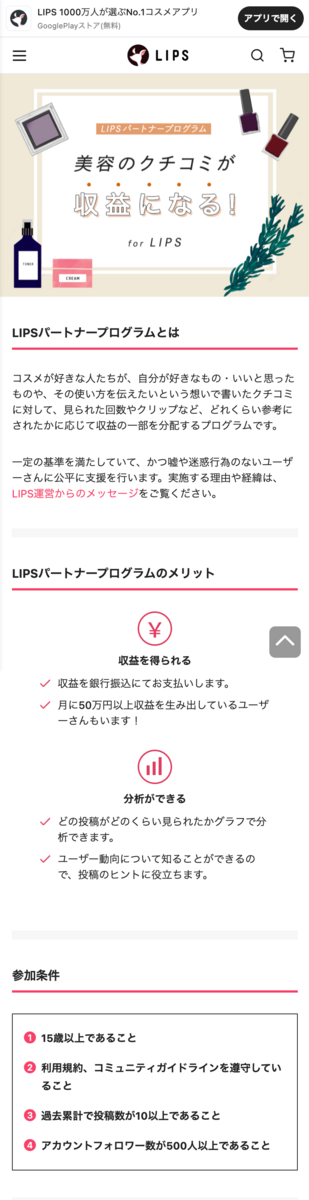
LPのフロントエンド実装にも取り組みました。こちらは実装したページのひとつであるLIPSパートナープログラムのLPです。
また、データベース周りのタスクにも取り組みました。
カラーコンタクトは他のコスメ商品と異なり、含水率やDIAなどのコンタクト特有の情報がユーザーに必要とされています。
そこで、DBにそのようなコンタクト特有の情報を保存し、下記のように商品詳細ページに表示するようにしました。

特定の領域を触りたいというよりもWeb開発のさまざまな開発を経験したかったので、 私の希望を汲んでこれまでのスキルセットにはない仕事も任せてもらえて、とても良い経験になりました。
投稿のタイトル自動生成
ここでは、取り組んだ中で大きなタスクの1つである投稿のタイトル生成について紹介します。(このタスクには、ChatGPTが登場する前の2022年に取り組んだもので、もし今やるならGPTを使うのが妥当かもしれません。)
LIPSで投稿を作成する際には、ユーザによるタイトルの入力はありません。 そのため、タイトルのようなものがあると嬉しい場合には、 人手でタイトルをつける必要がありました。
それでは何百万件もある投稿全てにタイトルをつけたりすることはできないので、次のような要件のタイトルを自動生成にすることになりました。
- ~50文字くらい
- 似たり寄ったりのタイトルではなく投稿固有のユニークなもの
代表文抽出
タイトル生成、つまり文書要約タスクには大きく分けて抽出型要約・抽象型要約があります。 抽出型要約は文書から代表となる1文を抽出することに対し、抽象型要約は1から要約文を生成します。
まずはじめに、投稿文の中から代表文となるような1文をタイトルとする抽出型要約を試しました。 抽象型要約では、ユーザーが意図していないタイトルや、好ましくない表現が生成されてしまう可能性があります。 一方で抽出型要約では、必ずユーザーが書いた文を使用するためそのようなリスクは少ないと考え、この手法を試すことにしました。
代表文の選定方法は、以下3つの手法を比較しました。
- tf-idfに基づくベクトルにおいて投稿全体と類似度の高い文
- 投稿全体の分散表現の平均と類似度の高い文
- 投稿全体の分散表現と類似度の高い文
分散表現はsentence-transformersを用いて、sonoisa/sentence-bert-base-ja-mean-tokens-v2モデルにて取得しました。
これらの手法では、各文と比較しているのが投稿全体のベクトル表現であるため、タイトルにしたい代表文の選定には向いておらず、あまり良い結果を得ることはできませんでした。
また抽出型の機械学習モデルを学習させる方法も考えましたが、代表文の教師データがすぐに用意できなかったため断念しました。
要約文生成
次に、抽象型要約を試しました。 これまで、人手で作成されたタイトルが教師データとして用いることでFine-tuningが可能となり、代表文抽出よりも高い精度が期待できそうでした。
しかし、要約の精度が高ければユーザーが意図していないタイトルは回避することができますが、先ほど触れた好ましくない表現が生成されてしまうケースは問題となります。 そこで、タイトルに含まれて欲しくないNG表現リストと照らし合わせ、要約された文にその表現が含まれていたらその要約文と似た1文をタイトルとすることにしました。
まず、投稿文から要約文を生成します。 これにはmegagonlabs/t5-base-japanese-webモデルを用いて、人手で作成されたタイトル約8,000件を教師データとして追加学習を行いましたが、この時点で精度は十分高くなりました。
NG表現が含まれていた場合は、sonoisa/sentence-bert-base-ja-mean-tokens-v2モデルを用いて、生成された要約文と類似度が高い1文をタイトルとしました。 *1
しかし単に類似度が高い1文をタイトルとすると、抽出された一文が短すぎたりタイトルとしては不適当なものが含まれていました。 文区切りは、Ginzaライブラリによって行っていますが、LIPSの投稿文は句読点が少なく、絵文字や記号を含み、口語で書かれることが多いため区切りが難しいことが原因として挙げられます。 そのため2文をつなげた文も候補に追加することで、不十分な文区切りを補うことにしました。
その後細々した後処理を行い、全投稿文のタイトルを生成し、さらに追加・編集された投稿のタイトルも自動で生成されるジョブまで実装しました。
仕事の進め方
基本的にはメンターのPinさんとやりとりをして仕事を進めていましたが、わからないことや何か詰まった時にはSlackの該当チャンネルで質問すると誰かしらがすぐに反応してくれて仕事が進めやすかったです。
また、Jobを積みすぎてcronを詰まらせたり、カラムの中身消しちゃったり3年間で色々やらかしたこともありましたが、 対応法を教えてもらったり、再発しないための対策を一緒に考えたり、合理的な対応をしていただき、成長する機会にもなりましたし。
リモート中心だったため(3年間で10回くらいしか出社したことない)、基本的にSlackでコミュニケーションをとって、長引きそうならHuddleやGoogle meetで通話、というような形でした。 しかしバリューに掲げられているとおりOPENな雰囲気で、Slackで気軽に発言できる環境だったため、リモートワークでも働きやすかったと感じています。
社内の雰囲気
リモートワーク中心ですがたまに出社すると社内の雰囲気は明るく、仕事もしやすい雰囲気でした。
在籍していた中で、特に楽しかったことの一つは酒部の活動です。 会社にある部活動のひとつですが、インターンでも歓迎してくれてよく参加していました。

先日送別会までしていただいて、最後までとても楽しかったです🍻
おわりに
働く場所の選び方としてよく「優秀な人と働くのが良い」と聞きますが、AppBrewはエンジニアの方も他職種の方もエネルギーがあって、たくさん勉強していて、仕事ができる方が多く刺激を受けることが多かったです。 学生のうちからエンジニアとして働きたい方にはぜひおすすめの職場なので、ぜひ応募してみてください!
*1:他のモデルやtf-idfによる類似度計算なども試した上で、最も性能が良かったものを選びました。